What is Data Observability? 5 Pillars You Need To Know
To Nha Notes | Sept. 18, 2022, 1:27 p.m.
My data observability definition has not changed since I first coined it in 2019.
Data observability is an organization’s ability to fully understand the health of the data in their systems. It eliminates data downtime by applying best practices learned from DevOps to data pipeline observability.
Data observability tools use automated monitoring, alerting, and triaging to identify and evaluate data quality and discoverability issues. This leads to healthier pipelines, more productive teams, and happier customers.
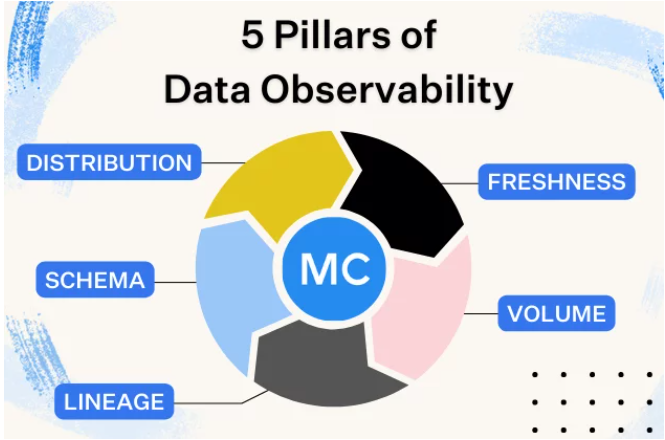
The five pillars of data observability are:
- Freshness
- Distribution
- Volume
- Schema
- Lineage
With monitors as code, data engineers can configure monitors via
a YAML config file and apply those monitors easily as part of the
build process or within their CI/CD process. Here's why it's a
must-have for your data observability tool:
- It’s maintained in source control so changes are properly tracked and approved
- It can be automated (e.g. you can easily create 100 monitors without repetitive UI clicking, you can enforce certain standards, etc.
- It naturally fits into the data engineering workflow (which consists of writing code, tests, and now, monitors.)
- It makes creating new monitors consistent and predictable, and less error-prone (e.g. you won’t get someone accidentally deleting/updating monitors.)
To support the growing demand for data democratization and
decentralized data ownership while meeting your company's strict
compliance needs, your data observability platform should:
- Offer SOC-2 Type II certification
- Never extract or store individual records, PII, or other sensitive information outside of your environment
- Allow you to comply with HIPAA, PCI, GDPR, CCPA, FINRA, and other compliance frameworks that you are subjected to
- Allow easy and simple deployment with little to no ongoing operational overhead and frequent automatic upgrades
- Provide a robust customer support experience that is quick, considerate of user needs and diverse tech stacks, and provides extensive documentation.
Data observability automatically monitors across key features of your data ecosystem, including data freshness,
distribution, volume, schema, and lineage. Without the need for manual threshold setting, data observability
answers such questions as:
● When was my table last updated?
● Is my data within an accepted range?
● Is my data complete? Did 2,000 rows suddenly turn into 50?
● Who has access to our marketing tables and made changes to them?
● Where did my data break? Which tables or reports were affected
References
https://www.montecarlodata.com/blog-what-is-data-observability/