Streaming Data Ingestions with Kafka and Debezium
To Nha Notes | Jan. 2, 2022, 12:03 p.m.
When it comes to ingesting data from a CDC system such as MySQL binlogs or Postgres WALs, there’s no simple solution without some help from a great framework.
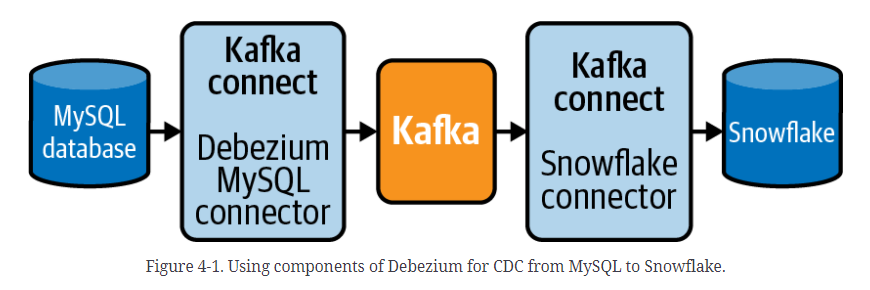
Debezium is a distributed system made up of several open source services that capture row-level changes from common CDC systems and then streams them as events that are consumable by other systems. There are three primary components of a Debezium installation:
- Apache Zookeeper manages the distributed environment and handles configuration across each service.
- Apache Kafka is a distributed streaming platform that is commonly used to build highly scalable data pipelines.
- Apache Kafka Connect is a tool to connect Kafka with other systems so that the data can be easily streamed via Kafka. Connectors are built for systems like MySQL and Postgres and turn data from their CDC systems (binlogs and WAL) into Kakfa topics.
Debezium ties these systems together and includes connectors for common CDC implementations. There are connectors already built to “listen” to the MySQL binlog and Postgres WAL. The data is then routed through Kakfa as records in a topic and consumed into a destination such as an S3 bucket, Snowflake, or Redshift data warehouse using another connector.
As of this writing, there are a number of Debezium connectors already built for source systems that you may find yourself needing to ingest from:
- MongoDB
- MySQL
- PostgreSQL
- Microsoft SQL Server
- Oracle
- Db2
- Cassandra
There are also Kafka Connect connectors for the most common data warehouses and storage systems, such as S3 and Snowflake.
If you want to use CDC at scale, I highly suggest using something like Debezium rather than building an existing platform like Debezium on your own
Reference from https://learning.oreilly.com/library/view/data-pipelines-pocket/9781492087823/ch04.html#stream-w-kafka-debezium