Cut Costs by Querying Snowflake from DuckDB
To Nha Notes | May 29, 2025, 4:54 p.m.
In the evolving landscape of data analytics, the integration of open table formats like Apache Iceberg with versatile query engines such as DuckDB is reshaping how organizations manage and query their data. This synergy offers a cost-effective, flexible, and efficient approach to data warehousing and lakehouse architectures.Wikipedia+4Medium+4Definite.app+4
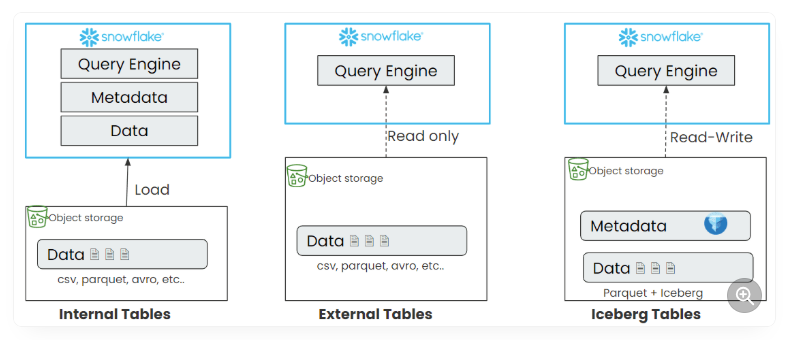
Key Differences Between Snowflake Native Tables and Iceberg Tables
-
Table metadata is stored in Iceberg format in public cloud storage and optionally in Snowflake if Snowflake is used as a catalog.
-
Data is stored in parquet format in public cloud storage, not in Snowflake.
-
Both Snowflake and external compute engines like Spark can read data from cloud storage and write back to the same location.
Iceberg Table Types in Snowflake
Depending on where the catalog is managed for Iceberg tables, Snowflake can have two types of Iceberg tables:
-
Snowflake Managed Iceberg Tables – Snowflake manages the metadata and catalog for these tables. These tables can support all Snowflake features with read and write access.
-
Externally Managed Iceberg Tables – An external system such as AWS Glue manages the metadata and catalog. These tables can support read-only access in Snowflake.
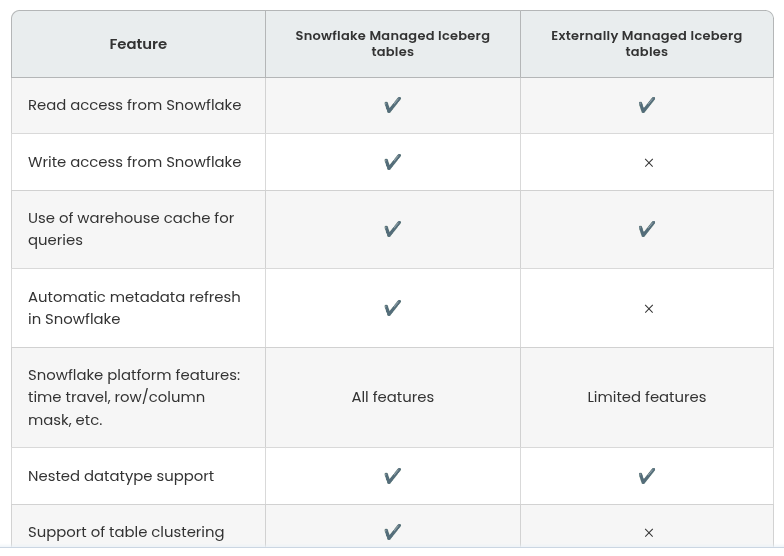
Embracing Apache Iceberg for Enhanced Data Management
Apache Iceberg, developed by Netflix and now an Apache Software Foundation project, addresses the limitations of traditional Hive-formatted tables. It introduces features like ACID transactions, time travel, and schema evolution, enabling robust data lakehouse capabilities. By abstracting table metadata from the underlying data storage, Iceberg allows multiple engines to interact with the same data seamlessly, promoting interoperability and reducing vendor lock-in. Medium+1Wikipedia+1Wikipedia+1Medium+1
DuckDB: A Lightweight Powerhouse for Query Execution
DuckDB is an in-process SQL OLAP database management system designed for efficient analytical query execution. Its lightweight nature allows it to run directly within applications without the need for a separate server, making it ideal for scenarios where simplicity and performance are paramount. DuckDB's ability to efficiently process data stored in formats like Parquet aligns well with Iceberg's storage mechanisms, facilitating seamless integration.
Cost Optimization: Querying Snowflake Data with DuckDB
Snowflake's adoption of Apache Iceberg enables external table support, allowing data stored in Iceberg format to be queried using Snowflake's engine. However, leveraging DuckDB to query this data can lead to significant cost savings. By offloading certain query workloads to DuckDB, organizations can reduce reliance on Snowflake's compute resources, thereby optimizing expenses without compromising on performance. Definite.app+7Medium+7Wikipedia+7Medium
Comparative Analysis of Iceberg-Compatible Query Engines
A comprehensive evaluation of various query engines reveals the following insights:
-
Snowflake: Offers robust features and seamless integration with Iceberg but may incur higher costs due to its compute pricing model.
-
Spark: Ideal for large-scale data processing with support for complex transformations, though it requires substantial infrastructure and expertise.Definite.app+5Wikipedia+5Definite.app+5
-
Trino: Provides fast, distributed SQL query execution with a focus on low-latency analytics, suitable for interactive querying.
-
DuckDB: Excels in scenarios requiring lightweight, in-process analytics, offering a balance between performance and resource utilization.
Conclusion
Integrating Apache Iceberg with query engines like DuckDB presents a compelling approach to modern data analytics. This combination not only enhances flexibility and interoperability but also offers avenues for cost optimization. As data ecosystems continue to evolve, embracing such synergistic technologies will be pivotal in building efficient, scalable, and economical data infrastructures.arXiv+2Wikipedia+2Medium+2
References:
-
Merlevede, J. (2024, May 15). Quack, Quack, Ka-Ching: Cut Costs by Querying Snowflake from DuckDB. Data Minded. Retrieved from https://medium.com/datamindedbe/quack-quack-ka-ching-cut-costs-by-querying-snowflake-from-duckdb-f19eff2fdf9d
-
Wang, S. (2024, July 3). Comparing Iceberg Query Engines. Definite. Retrieved from https://www.definite.app/blog/iceberg-query-engine
-
https://buremba.com/blog/use-snowflake-and-duckdb-with-iceberg?ref=blef.fr
-
https://greybeam.medium.com/iceberg-tables-in-snowflake-an-introduction-ef67459d0b52
-
https://medium.com/snowflake/an-overview-of-snowflake-apache-iceberg-tables-d5e85864ac99
-
https://github.com/datamindedbe/blog-platform-quack-quack-ka-ching