Crafting a Whiteboard Architecture for a Data Platform
To Nha Notes | March 19, 2024, 10:16 a.m.
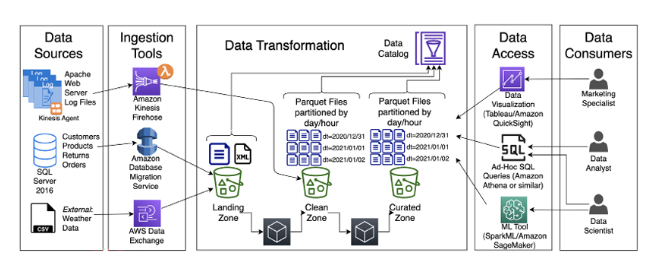
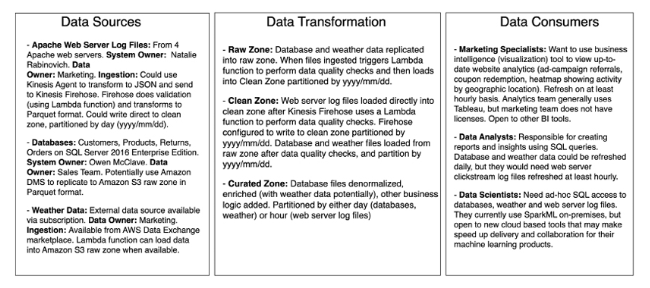
-
Data Ingestion:
- Consider using a streaming platform (such as Apache Kafka or Amazon Kinesis) alongside batch-based ingestion tools. Streaming allows real-time data processing and reduces latency.
- Integrate schema validation during ingestion to ensure data quality and consistency.
-
Data Transformation:
- Instead of a single “Clean Zone,” consider a more modular approach:
- Raw Zone: Store raw data as-is for historical purposes.
- Staging Zone: Perform initial data cleaning, validation, and enrichment.
- Curated Zone: Processed data ready for consumption.
- Implement data lineage tracking to understand transformations and lineage across zones.
- Instead of a single “Clean Zone,” consider a more modular approach:
-
Data Storage:
- Explore cloud-native storage solutions like Amazon S3 or Google Cloud Storage for scalability and cost-effectiveness.
- Use columnar storage formats (e.g., Parquet) for efficient querying and compression.
-
Data Catalog and Metadata:
- Establish a centralized metadata repository to track data assets, lineage, and business context.
- Leverage tools like Apache Atlas or AWS Glue for automated metadata management.
-
Data Access and Querying:
- Consider using a data virtualization layer (e.g., Presto, AWS Athena) to provide unified access to data across zones.
- Enable fine-grained access control to restrict data access based on roles and permissions.
-
Monitoring and Observability:
- Implement real-time monitoring for data pipelines, including alerts for failures or anomalies.
- Use tools like Prometheus or Datadog for observability.
-
Security and Compliance:
- Integrate encryption at rest and in transit for data security.
- Ensure compliance with data privacy regulations (e.g., GDPR, CCPA).