Data Engineering Weekly #266
Newsletter Content
Free Course: AI-Driven Data EngineeringAI coding agents are changing how data engineers work. This Dagster University course shows how to build a production-ready ELT pipeline from prompts while learning practical patterns for reliable AI-assisted development. Animesh Kumar: AI-Ready Data vs. Analytics-Ready Data
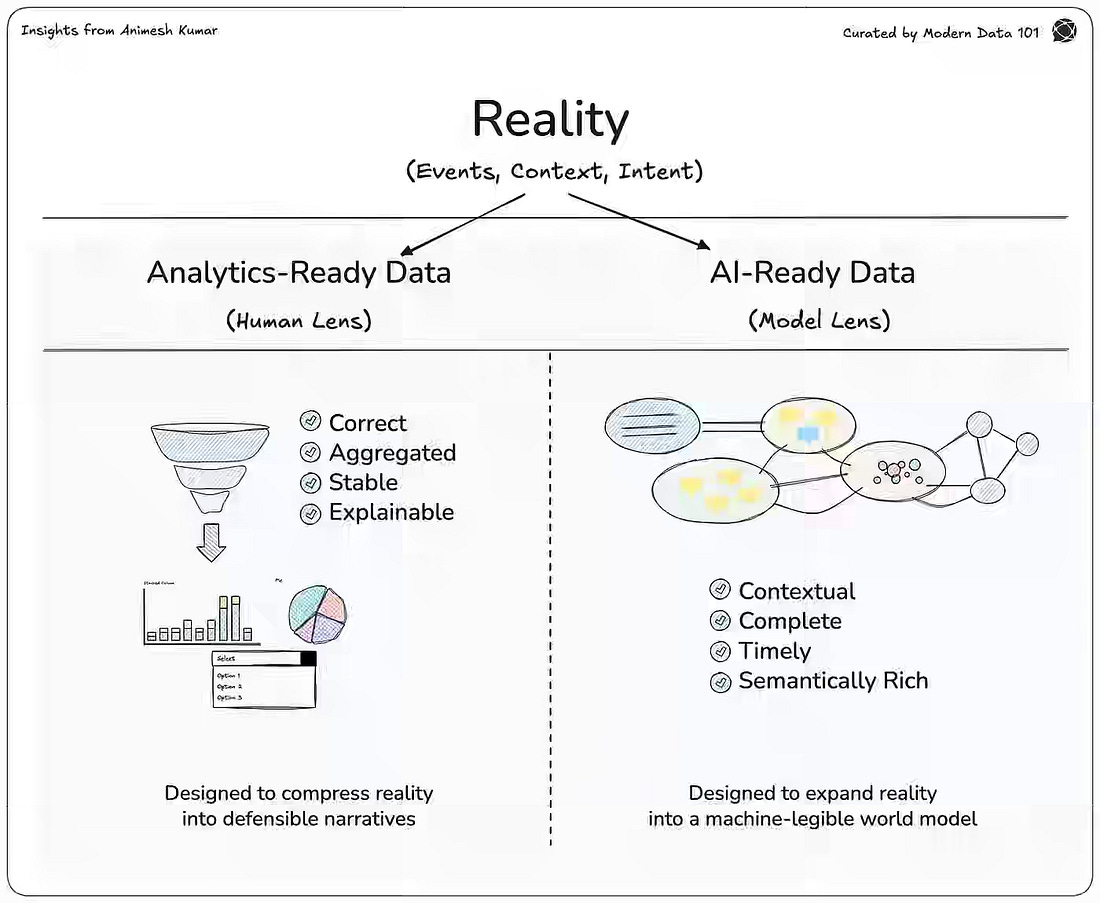
Analytics and AI systems fail when teams treat data readiness as a single maturity path instead of two distinct axes optimized for different consumers. The author distinguishes analytics-ready data—designed for human interpretation through aggregation, stability, and explainability—from AI-ready data, which requires contextual completeness, timeliness, and semantic richness often lost in aggregation pipelines. https://medium.com/@community_md101/ai-ready-data-vs-analytics-ready-data-f67ef0804341 Whatnot: The model is the easy part: Building the LLM Platform at Whatnot
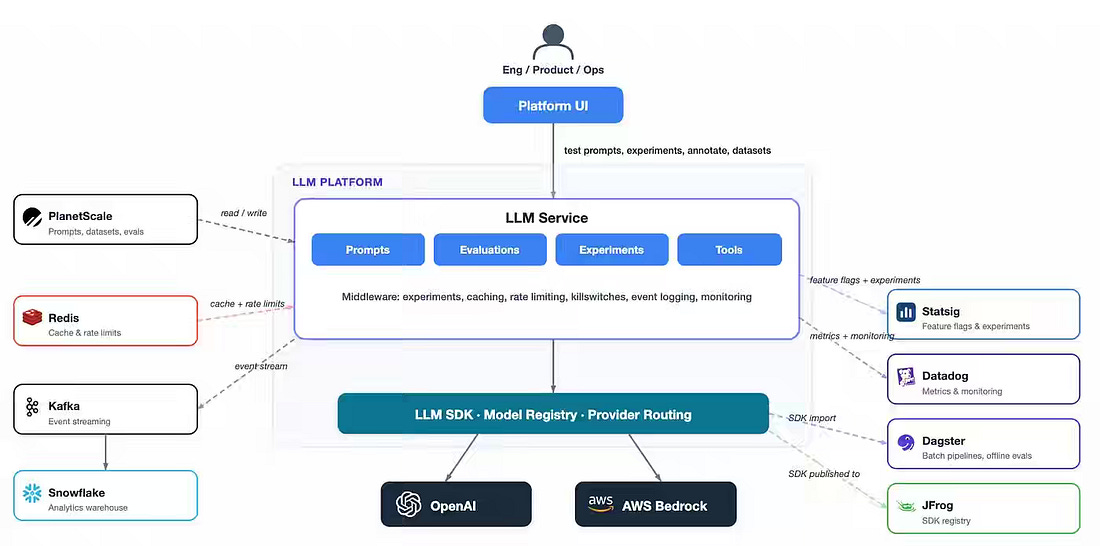
Production LLM systems fail primarily in the surrounding infrastructure rather than the model layer, where non-deterministic outputs, unconstrained inputs, and missing feedback loops undermine reliability and trust. Whatnot writes about structuring its LLM platform around three pillars—velocity, reliability, and trust. It uses the post-exposure A/B logging to isolate divergent outputs, a reusable tool registry, and LLM-as-a-judge calibration workflows to detect production drift early. Slack: Managing context in long-run agentic applications
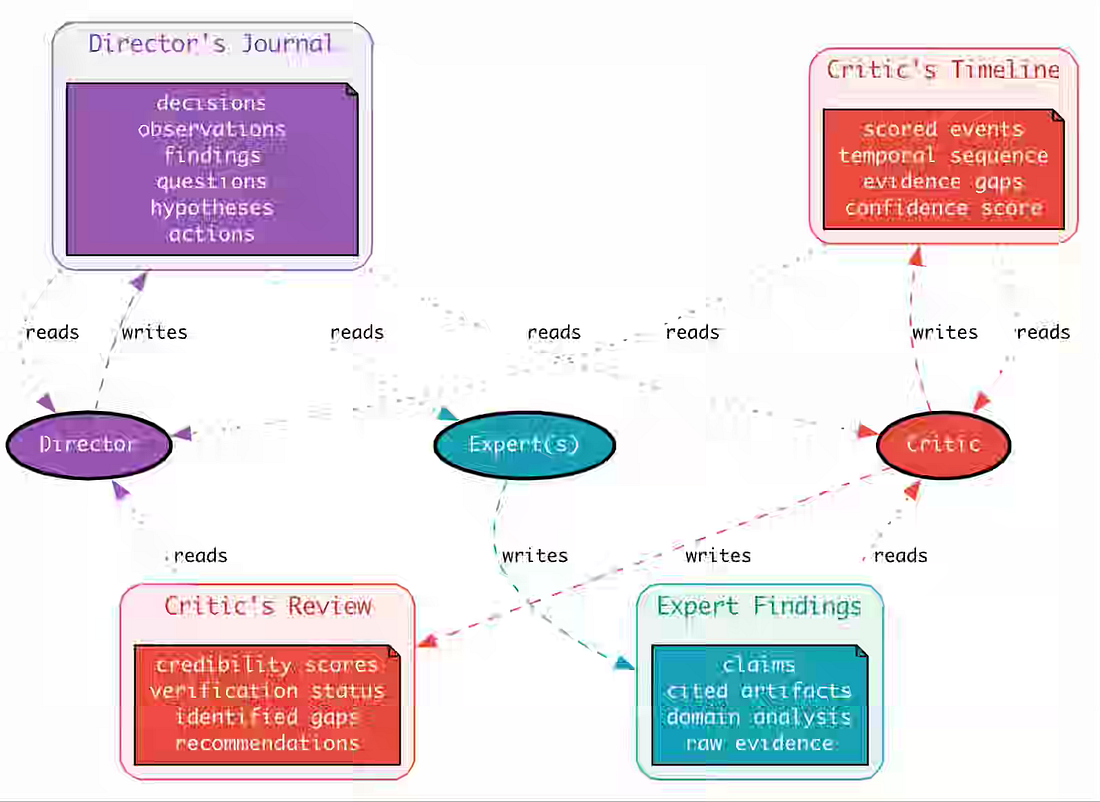
Long-running multi-agent systems lose investigative coherence as stateless LLM APIs force context accumulation, degrading reasoning quality and amplifying hallucinations across rounds. Slack writes about addressing this with three context channels—a Director’s Journal for working memory, a Critic’s Review that scores findings on a five-level credibility rubric, and a Critic’s Timeline that prunes incoherent findings by enforcing narrative consistency. https://slack.engineering/managing-context-in-long-run-agentic-applications/ Sponsored: The AI Modernization Guide
Will your data platform accelerate your AI initiatives or become their biggest bottleneck? Learn how to build a data platform that's ready for AI: Atlassian: Engineering the Forge Billing Platform for Reliability and Scale
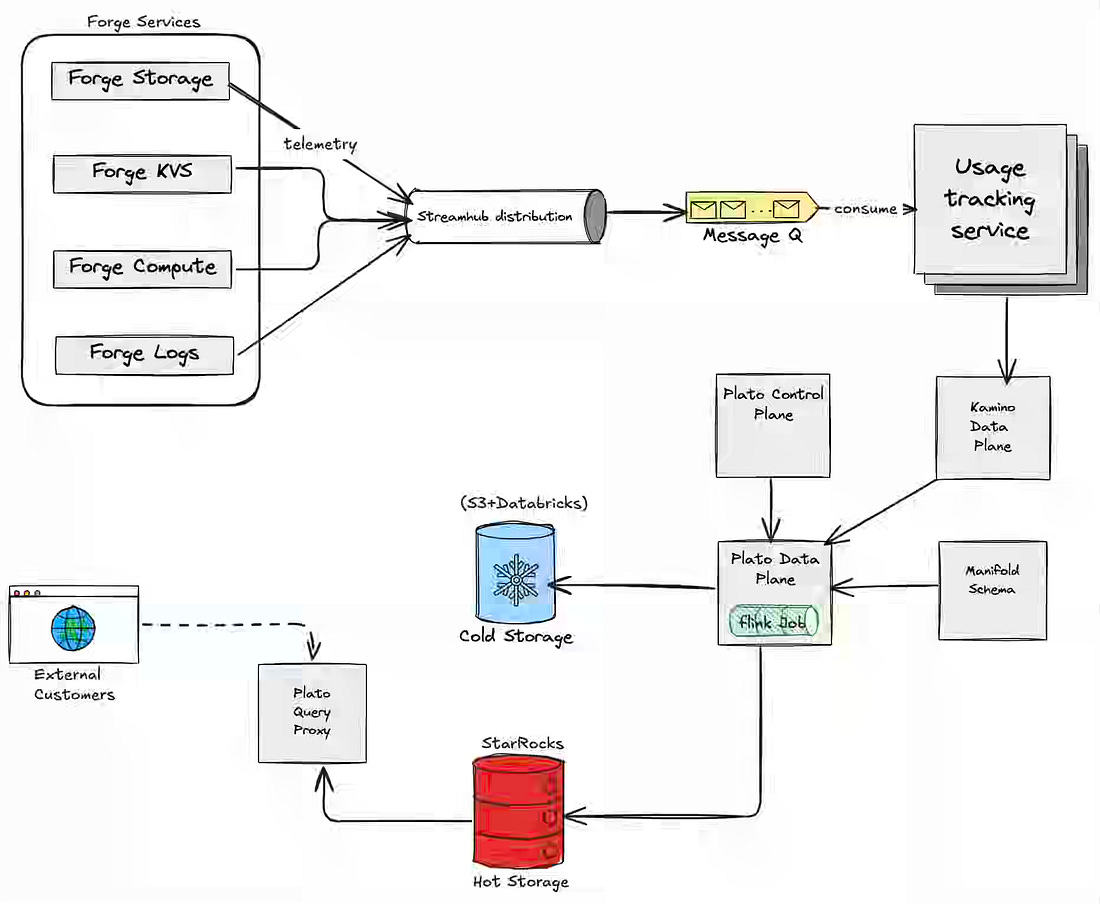
The billing pipeline, especially the usage-based billing pipeline, is often very complex, given the system's sensitivity to correctness. Atlassian describes Forge Billing as a deterministic pipeline—routing 300M daily usage events through StreamHub and UTS for deduplication and schema validation, then splitting them into cold-tier raw storage and StarRocks hot-tier aggregations for fast developer queries. The architecture handles counter and gauge metrics through idempotency keys and last-write-wins windowing, enabling full charge traceability from Developer Console back to raw events while scaling to 1B daily events within a year. Giannis Polyzos: From Events To Real-Time Profiles On Apache Fluss
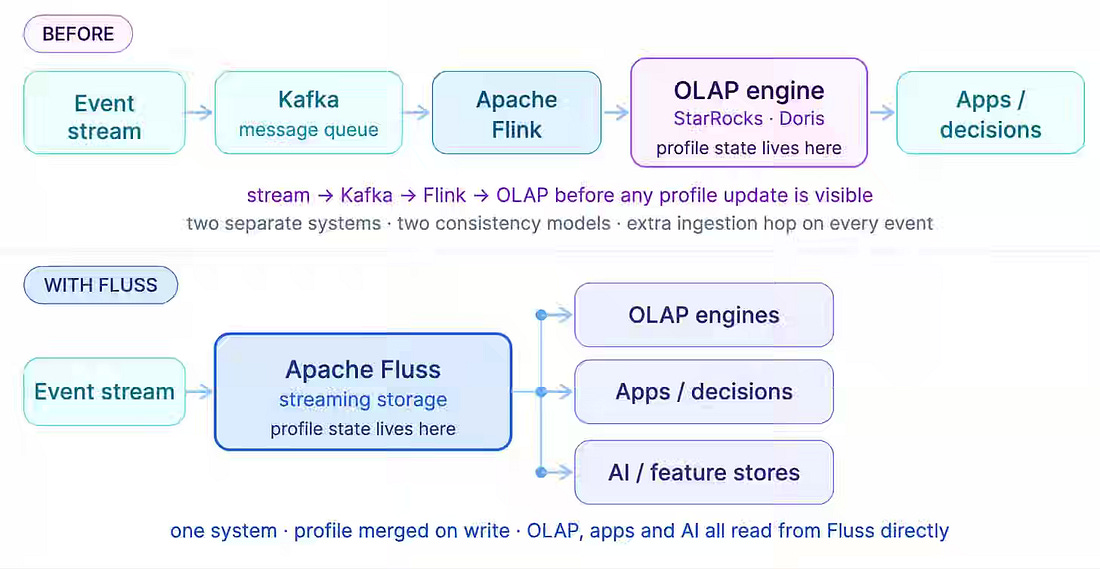
Real-time entity decisions fail when profile state lives in a separate OLAP layer, introducing ingestion lag between event arrival and visibility. The approach builds risk profiles directly in Apache Fluss by mapping identifiers to integers, encoding group membership as Roaring Bitmaps, and merging updates at write time using the Aggregation Merge Engine without stateful Flink jobs. This design removes the need for a separate profile store, reduces state latency from hours to seconds, and ensures correct recovery through replay-safe inverse operations in the UndoRecoveryOperator. https://ipolyzos.substack.com/p/from-events-to-real-time-profiles Thiago Baldim: The journey to Agentic BIAgentic BI tools amplify data quality issues—ambiguous schemas, undocumented columns, and fragmented sources of truth—rather than resolving them at query time. SafetyCulture writes about rebuilding its data platform on Kimball architecture with SCD Type 2 dimensions, over 90% dbt test and documentation coverage, and column-level ownership aligned to business stakeholders, reducing pipeline execution time from 14 hours to 1.5 hours. https://medium.com/@thiagobaldim/the-journey-to-agentic-bi-617975c106b7 Pinterest: Scaling Recommendation Systems with Request-Level Deduplication
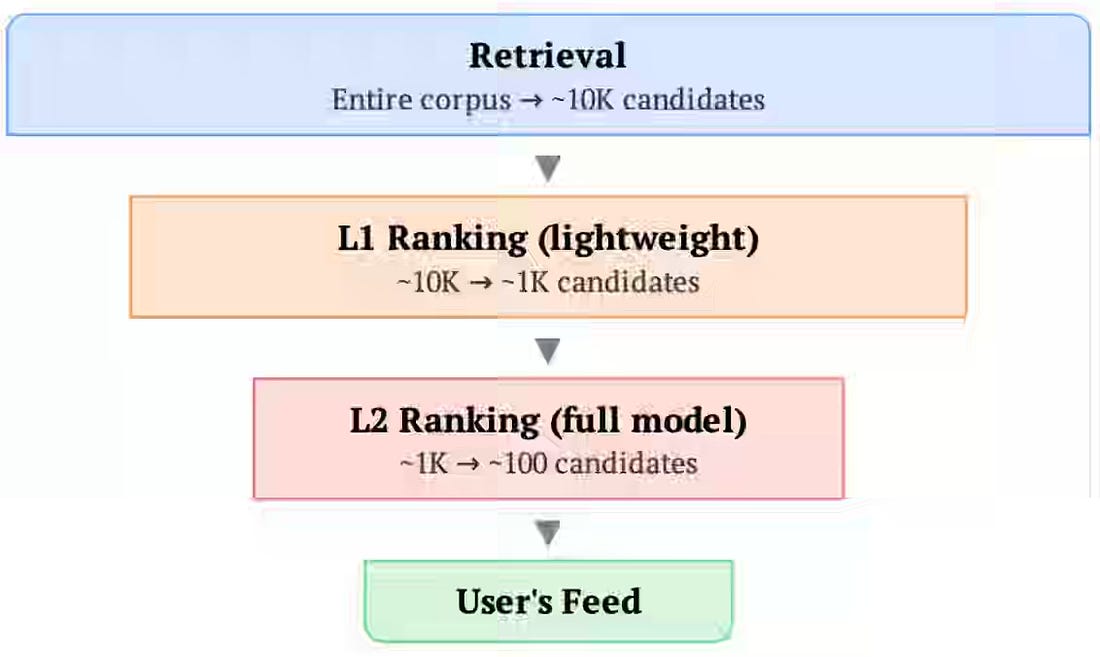
Scaling recommendation models creates infrastructure pressure because request-level data—especially long user action sequences—is redundantly stored and processed once per candidate item across storage, training, and serving. Pinterest writes about applying request-level deduplication across the ML lifecycle using request-sorted Iceberg datasets, SyncBatchNorm, and user-level masking to preserve training correctness, and a Deduplicated Cross-Attention Transformer that caches user context for reuse across ranked items. Just Eat: Daedalus and the Data LabyrinthData governance fails when organizations share data without sharing definitions, ownership, lineage, and reusable business logic across the systems humans and AI agents rely on. Just Eat frames modern governance as a layered navigation system—combining a business glossary, data catalog, metadata, data quality signals, lineage, and a semantic layer—to connect business language with trusted data assets and machine-usable definitions. These governance layers turn complex data platforms from opaque labyrinths into navigable systems, enabling consistent analytics, more reliable AI-generated queries, and a lower risk of conflicting metrics. https://medium.com/justeattakeaway-tech/daedalus-and-the-data-labyrinth-2c166b1d9866 Teads: We Let AI Agents Orchestrate Our ML Experiments
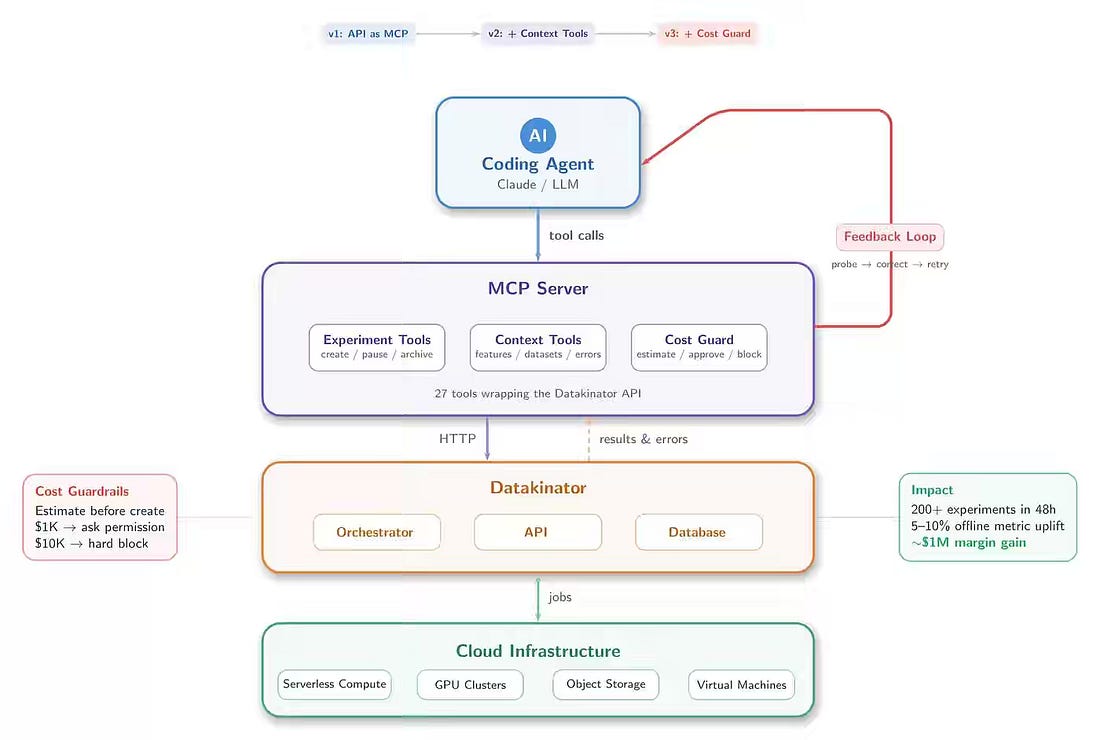
Teads writes about extending its Datakinator platform with agentic orchestration by exposing APIs through MCP, enriching them with dataset probing and error-retrieval tools, and adding cost guardrails that estimate and gate expensive runs. This approach scales experiment throughput from hundreds to thousands, enables autonomous retry and correction of failed runs, and delivers 5–10% model improvements that translate to nearly $1M in margin gains despite increased cloud usage. https://medium.com/teads-engineering/we-let-ai-agents-orchestrate-our-ml-experiments-fc8606816fde All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
|


Details
Source:
Other
Date:
Apr 20, 2026 10:09
Category:
Technical