Revisiting Medallion Architecture: Data Vault in Silver, Dimensional Modeling in Gold
Newsletter Content
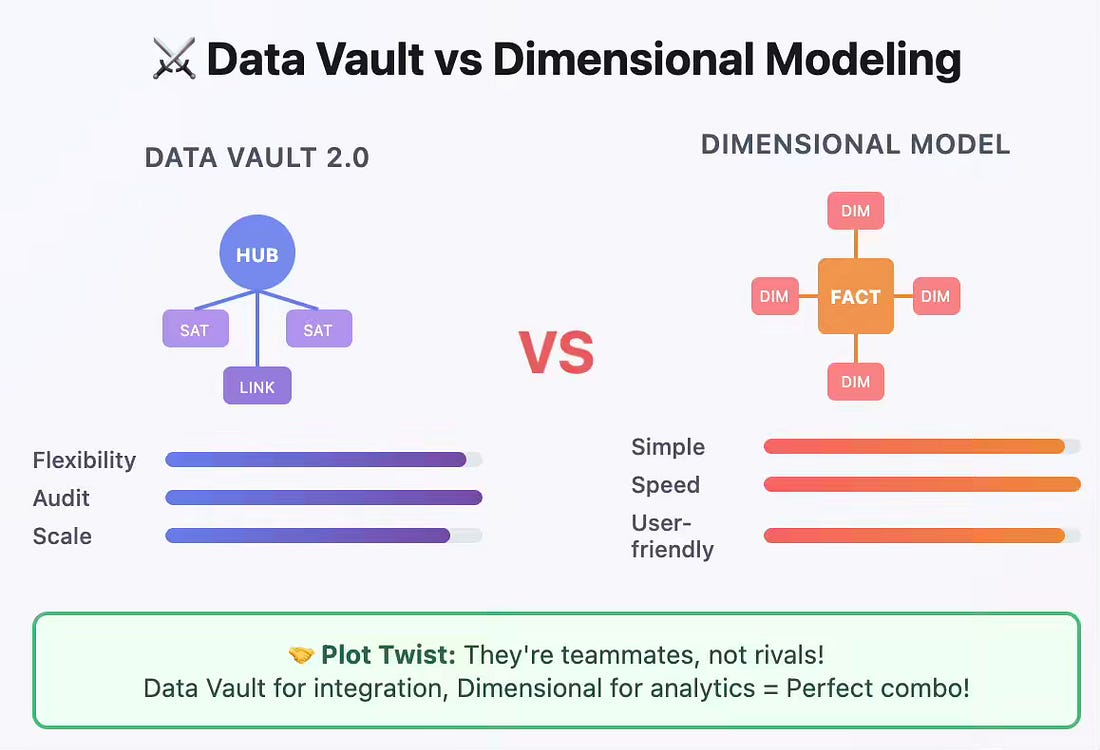
Revisiting Medallion Architecture: Data Vault in Silver, Dimensional Modeling in GoldHow to Balance Flexibility and Performance in a Modern Data PlatformFor more than two decades, the data warehousing community has grappled with a fundamental and largely misplaced debate: whether Data Vault or dimensional modeling produces a “better” data warehouse. Each camp has spent years evangelizing its methodology as superior, assuming that a singular modeling paradigm could—or should—address every requirement in a modern analytics platform. What is the consequence of this binary thinking? Organizations have invested heavily in architectures that, while optimized for one objective, fail catastrophically in others. Rigid star schemas provide blazing-fast analytics but crack under schema changes. Data Vaults offer unmatched schema flexibility and auditability but impose significant query complexity and performance limitations.
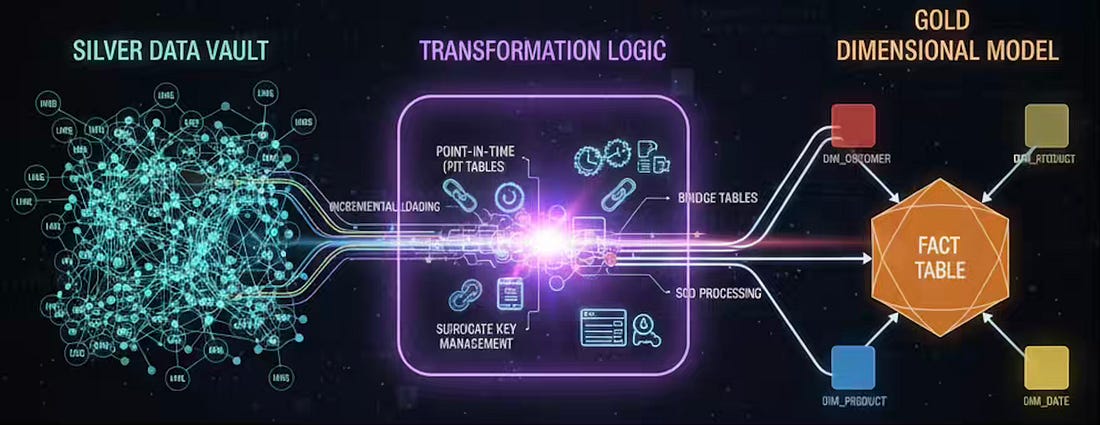
Modern data platforms have evolved beyond monolithic warehouse architectures. The rise of the medallion architecture—Bronze, Silver, Gold—presents an opportunity to align data modeling strategies with the distinct goals of each layer. A best-practice implementation of this architecture often looks like this: raw data lands in Bronze, is integrated and historized into a Data Vault model in the Silver layer, and is then transformed into performance-optimized dimensional models in the Gold layer for consumption. In this model:
This article explores the architectural insight that has quietly become an industry best practice: use Data Vault in Silver and dimensional modeling in Gold. This pattern didn’t emerge from ideology but from pragmatism. It resolves structural tensions that have plagued data teams for decades and offers a blueprint for scalable, auditable, and performant data platforms. Part I: Understanding the Core Tradeoff — Flexibility vs. Performance
This tradeoff is not an opinion; it’s a direct consequence of data modeling choices.
Dimensional Modeling: Optimized for ReadingPopularized by Ralph Kimball, dimensional modeling is purpose-built for performance and user experience. It pre-joins and denormalizes data into wide fact and dimension tables (a “star schema”) that reflect how business users ask questions. Example: A This structure is highly optimized for read-heavy analytical queries. Minimizing the number of joins at query time enables analytical databases to scan massive volumes of data efficiently. However, this performance comes at the cost of flexibility. It is inherently brittle:
Data Vault: Optimized for Writing and IntegrationData Vault, by contrast, was designed explicitly for schema flexibility and historical traceability. Its hub-link-satellite structure is highly normalized, separating business keys (Hubs), relationships (Links), and descriptive attributes (Satellites). Benefits:
The cost of this flexibility is query performance. Reconstructing a simple business entity, such as a customer’s current profile, might require joining a hub to half a dozen satellites and filtering each for the latest record. This proliferation of joins makes ad-hoc analytical queries complex to write and slow to execute. Part II: Why Data Vault Belongs in Silver
The Silver layer is about integration, not direct analytics. It is the architectural control point where raw data from multiple sources becomes conformed, historical, and unified. For this purpose, Data Vault’s characteristics are not just helpful—they are ideal. Schema Evolution Without Disruption:Enterprises are dynamic. A new CRM is adopted, a business unit is acquired, and a third-party data feed is added. In a dimensional model, each change triggers a high-risk refactoring project. In Data Vault, integration becomes an additive, low-risk process. A new source system means loading new satellites attached to existing hubs. Pipelines for existing sources remain untouched, preventing the cascading failures that plague monolithic models. Parallel and Isolated ProcessingIn a dimensional load, fact tables cannot be loaded until all their corresponding dimension keys exist. This creates rigid dependencies. Data Vault’s decoupled architecture enables parallel ingestion. Hubs (business keys), links (relationships), and satellites (attributes) can all be loaded independently and in any order. A failure in the pipeline loading customer addresses doesn’t halt the pipeline loading customer transactions. Operational resilience and fault isolation are critical for managing complex environments at scale. Structural Auditability and Time TravelEvery row in a satellite table includes metadata, including the load timestamp and the data source. Changes are captured by inserting new satellite rows, creating an immutable log. This structure allows you to answer critical audit questions without any extra tooling: “What did we know about this customer on January 15th, 2022, according to the billing system?” Reconstructing this historical state is a straightforward query, a feature that is indispensable for regulatory compliance and root-cause analysis. Preservation of Source SemanticsForcing data from multiple source systems into a single, “mastered” dimension table too early often leads to data loss or misinterpretation. One system might define a “customer” as an individual, while another might define it as a household. Data Vault allows these conflicting definitions to coexist peacefully in separate satellites attached to the same customer hub. The complex task of harmonizing these definitions can be deferred until the business logic is fully understood, typically during the transformation to the Gold layer. Write-Optimization by DesignModern data ingestion patterns, particularly Change Data Capture (CDC) and streaming, are based on append-only logs. Data Vault’s insert-only design is a natural fit for these patterns. This alignment with technologies like Kafka and Kinesis, and with platforms like Databricks Delta Lake and Apache Iceberg, means data can be written into the Silver layer with minimal transformation, preserving the raw change history and enabling highly efficient, parallel batch and stream ingestion. Part III: Why Dimensional Modeling Dominates Gold
The Gold layer is the presentation layer, purpose-built for business consumption. It serves human analysts, BI dashboards, KPIs, forecasts, and executive reports. In this arena, the performance, simplicity, and semantic clarity of dimensional modeling are unmatched. Aligns with Natural Business Mental ModelsBusiness users think in terms of dimensions (”by region,” “by product category,” “over time”). Star schemas directly model this mental map. The fact table contains business metrics (e.g., sales_amount), while dimension tables provide the descriptive context (e.g., dim_product, dim_customer). This intuitive structure allows users to easily slice, dice, and drill down into data. The hierarchies within dimensions (e.g., Country -> State -> City) translate directly to features in BI tools. Example:
Denormalization for Unmatched SpeedBy design, dimensional models pre-join and duplicate data for performance. In the age of columnar data warehouses (like Snowflake, BigQuery, and Redshift), this is a winning strategy. These systems are optimized for scanning wide tables, using techniques such as columnar compression and zone maps to reduce I/O dramatically. The storage “cost” of denormalization becomes negligible, while the query performance gains are massive. The result is the sub-second dashboard response time that business users demand. Robust Support for Slowly Changing Dimensions (SCD Type 2)Business context changes. A customer moves to a new city; a product is rebranded. Dimensional models have a standard, elegant pattern for tracking this history: the Type 2 Slowly Changing Dimension. When a change occurs, the old dimension row is expired (e.g., by setting an effective_end_date), and a new row is inserted with a new integer surrogate key and an effective_start_date. This ensures that historical facts always align with the version of the dimension that was active at the time, preserving the accuracy of trend analysis. Seamless BI Tool IntegrationBI tools like Tableau, Power BI, and Looker are architected around the assumption of a star schema. Their query generators, caching mechanisms, and UI components are optimized for clear fact-dimension joins and hierarchical drill-downs. Connecting these tools directly to a Data Vault is technically possible but, in practice, a nightmare, leading to user frustration, complex data source definitions, and poor performance. Dimensional models just work. Enforces Enterprise Metric ConsistencyA key goal of any data warehouse is to create a “single version of the truth.” Conformed dimensions are the mechanism for achieving this. By using a single, shared dim_date and dim_product across multiple fact tables (e.g., fct_sales, fct_inventory), an organization ensures that metrics are calculated consistently across departments. This eliminates arguments over whose numbers are “right” and builds a foundation of trust in the data. Part IV: The Hard Part — Bridging Silver to Gold
Combining Data Vault and dimensional modeling is elegant in theory. In practice, the transformation layer that builds Gold dimensional models from the Silver Data Vault is where the most complex engineering work lies. Success depends on mastering the following techniques. Point-in-Time (PIT) and Bridge TablesTo reconstruct an entity’s state without complex multi-satellite joins at runtime, you build Point-in-Time (PIT) tables. A PIT table contains a business key, a snapshot timestamp, and the specific hash keys of the satellite rows that were valid at that time. This turns a complex, multi-join query into a simple lookup. For resolving many-to-many relationships (e.g., customers and bank accounts), Bridge tables are built from the Link tables in the Data Vault. Surrogate Key ManagementData Vault uses hash keys based on business keys, while dimensional models use integer surrogate keys for performance and to handle SCDs. The transformation logic must maintain a persistent mapping table. When a new business key appears in a hub, the process looks it up in the map, generates a new integer key if it doesn’t exist, and uses that key in the final dimension and fact tables. SCD Processing from Multiple SatellitesBuilding a Type 2 dimension from a hub and multiple satellites requires sophisticated logic. The process must monitor changes across all relevant satellites for a given business key. When a change is detected in any of the source attributes, the logic must trigger the SCD process: expire the current dimension row and create a new one with the combined, updated state. Incremental LoadingRebuilding multi-billion-row fact and dimension tables nightly is cost-prohibitive and slow. The transformation layer must be incremental. This involves using watermarking (tracking the latest load timestamp from the Silver layer) to ensure that only new or changed Data Vault records are processed in each run. This requires careful state management and idempotent logic to ensure correctness and efficiency. Part V: When This Architecture Works — And When It Doesn’tThis architecture isn’t a silver bullet. It’s a strategic choice for a specific set of problems. When It Works Best
When to Avoid It
It is crucial to recognize that the cost of this architecture is not trivial. It requires significant, upfront investment in engineering discipline, robust orchestration (e.g., dbt, Airflow), and mature testing and deployment practices to manage the Silver-to-Gold transformation layer effectively. Part VI: Making It Work in PracticeExecution is everything. To make this model sustainable: Treat Transformation Logic as a ProductThis logic isn’t a collection of scripts; it’s a critical software asset. It must be version-controlled, have CI/CD pipelines for testing, be owned by a dedicated team, and be thoroughly documented. Invest Heavily in Metadata and AutomationDon’t hardcode transformation rules. Drive them from metadata. Use metadata to map satellites to dimensions, automate the generation of SCD logic, and track lineage. This makes the system more declarative and easier to maintain. Build Resilient, Incremental PipelinesAll transformations must be idempotent (rerunnable without side effects), delta-aware (processing only new data), and built on a foundation of partitioning and watermarking to control costs and ensure performance at scale. Structure Teams to Reflect LayersAlign team responsibilities with the architecture. Data engineers focus on the Bronze-to-Silver layer (ingestion, integration, Data Vault modeling). Analytics engineers own the Silver-to-Gold layer (business logic, dimensional modeling, performance). This specialization creates clear ownership and deep expertise. Part VII: The Future of Layered ModelingThis approach is the foundation upon which the next generation of data tooling is being built. The Semantic Layer: A Consumer of Gold
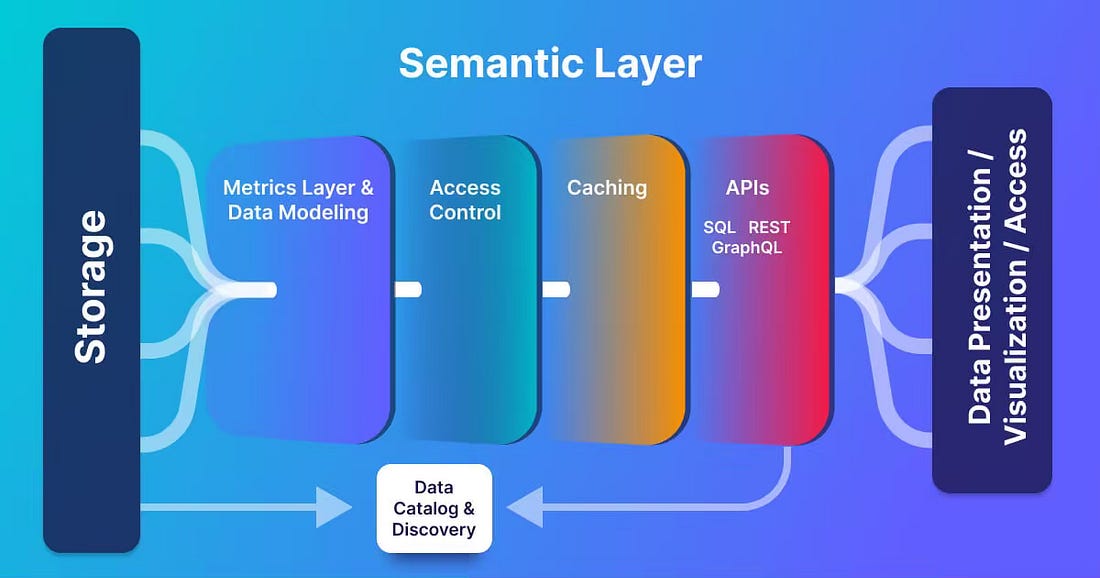
Tools like dbt Metrics, Cube, and MetricFlow are pushing business logic into a centralized semantic layer. This layer sits on top of the Gold layer, not within it. It consumes well-structured dimensional models and provides a stable, user-friendly translation of business metrics (e.g., “Active Users,” “Gross Margin”). This makes the quality and performance of the Gold dimensional model more critical than ever, as it is the foundation for all business-facing analytics. Hyper-Optimized Gold: The One Big Table (OBT)For the most performance-critical use cases, such as a flagship executive dashboard or a machine learning feature set, a standard star schema may not be fast enough. In these scenarios, teams can create a One Big Table (OBT)—a fully denormalized, wide table derived from the Gold dimensional models. The OBT is a final, purpose-built artifact within the Gold layer, sacrificing flexibility for maximum query speed. Metadata-Driven Data VaultFrameworks and platforms are emerging to automate the generation of hubs, satellites, and the associated loading patterns. This lowers the barrier to Data Vault adoption by abstracting away some of the implementation complexity and increasing consistency. AI-Assisted TransformationsLLMs and AI tools are becoming valuable assistants in this process. They can help accelerate development by generating boilerplate transformation SQL, writing documentation, and suggesting data quality tests, freeing up engineers to focus on more complex architectural decisions. Real-Time PipelinesAs the business demand for real-time data grows, the batch-oriented nature of this architecture is evolving. The convergence of batch and streaming means CDC data flowing into the Silver layer in near real-time must be reconciled into consistent, accurate dimensional models in the Gold layer, presenting new challenges for managing late-arriving data and ensuring transactional correctness. Final Thoughts: Solve the Right ProblemThe old debate—Data Vault vs. Dimensional Modeling—was a false dichotomy that missed the point. It was never about which model is better in isolation. It’s about which model is best suited to solve a specific problem at a specific stage of the data lifecycle:
The medallion architecture provides a framework for using both methodologies where they excel. Yes, the bridge between them is hard to build. It requires skill, discipline, and the right tooling. But once built, it creates a data platform that is simultaneously auditable, scalable, self-service ready, and perfectly aligned with business needs. Modern data teams must stop chasing architectural silver bullets. This layered approach isn’t simple—but it’s effective. When implemented well, it becomes a durable competitive advantage that few organizations can match. Choose deliberately. Build carefully. Test thoroughly. The payoff is worth it.
|


 | by Pratik Khedekar | Medium")

Details
Source:
Other
Date:
Oct 17, 2025 11:00
Category:
Technical