RAG
To Nha Notes | Feb. 18, 2025, 4:13 p.m.
RAG is a technique that enhances a model’s generation by retrieving the relevant information from external memory sources. An external memory source can be an internal database, a user’s previous chat sessions, or the internet.
With RAG, only the information most relevant to the query, as determined by the retriever, is retrieved and input into the model.
You can think of RAG as a technique to construct context specific to each query, instead of using the same context for all queries. This helps with managing user data, as it allows you to include data specific to a user only in queries related to this user.
In the early days of foundation models, RAG emerged as one of the most common patterns. Its main purpose was to overcome the models’ context limitations. Many people think that a sufficiently long context will be the end of RAG. I don’t think so. First, no matter how long a model’s context length is, there will be applications that require context longer than that.
Note
Anthropic suggested that for Claude models, if “your knowledge base is smaller than 200,000 tokens (about 500 pages of material), you can just include the entire knowledge base in the prompt that you give the model, with no need for RAG or similar methods” (Anthropic, 2024). It’d be amazing if other model developers provide similar guidance for RAG versus long context for their models.
RAG Architecture
A RAG system has two components: a retriever that retrieves information from external memory sources and a generator that generates a response based on the retrieved information.
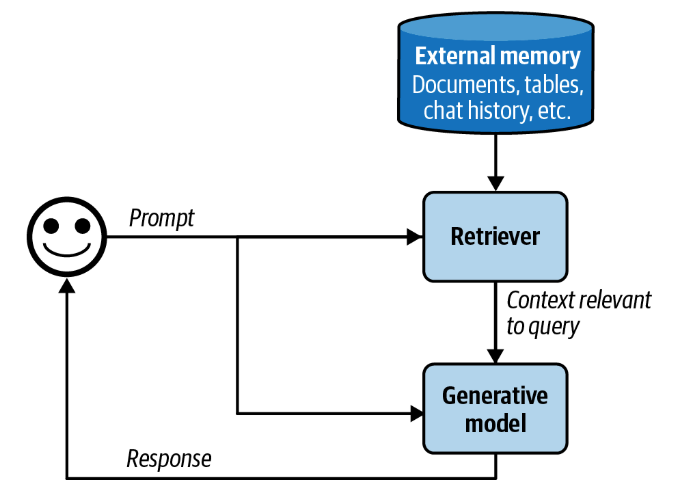
In today’s RAG systems, these two components are often trained separately, and many teams build their RAG systems using off-the-shelf retrievers and models. However, finetuning the whole RAG system end-to-end can improve its performance significantly.
The success of a RAG system depends on the quality of its retriever. A retriever has two main functions: indexing and querying. Indexing involves processing data so that it can be quickly retrieved later. Sending a query to retrieve data relevant to it is called querying. How to index data depends on how you want to retrieve it later on.
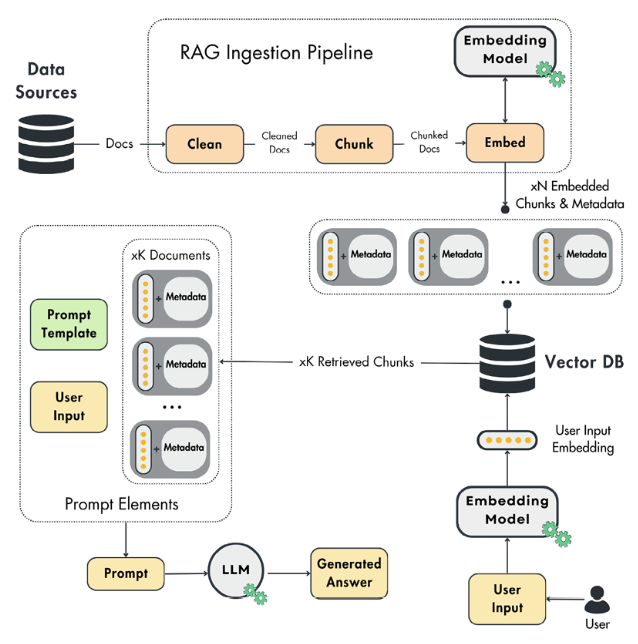
Vanilla RAG architecture
- On the backend side, the ingestion pipeline runs either on a schedule or constantly to populate the vector DB with external data.
- On the client side, the user asks a question.
- The question is passed to the retrieval module, which preprocesses the user’s input and queries the vector DB.
- The generation pipelines use a prompt template, user input, and retrieved context to create the prompt.
- The prompt is passed to an LLM to generate the answer.
- The answer is shown to the user.
You must implement RAG in your generative AI application when you need access to any type of external information. For example, when implementing a financial assistant, you most likely need access to the latest news, reports, and prices before providing valuable answers. Or, if you build a traveling recommender, you must retrieve and parse a list of potential attractions, restaurants, and activities. At training time, LLMs don’t have access to your specific data, so you will often have to implement a RAG strategy in your generative AI project.
Why use RAG?
We briefly explained the importance of using RAG in generative AI applications earlier. Now, we will dig deeper into the “why,” following which we will focus on what a naïve RAG framework looks like.
For now, to get an intuition about RAG, you have to know that when using RAG, we inject the necessary information into the prompt to answer the initial user question. After that, we pass the augmented prompt to the LLM for the final answer. Now, the LLM will use the additional context to answer the user question.
There are two fundamental problems that RAG solves:
- Hallucinations
- Old or private information
Hallucinations
If a chatbot without RAG is asked a question about something it wasn’t trained on, there is a high chance that it will give you a confident answer about something that isn’t true. Let’s take the 2024 European Football Championship as an example. If the model is trained up to October 2023 and we ask it something about the tournament, it will most likely come up with a random answer that is hard to differentiate between reality and truth. Even if the LLM doesn’t hallucinate all the time, it raises concerns about the trustworthiness of its answers. Thus, we must ask ourselves: “When can we trust the LLM’s answers?” and “How can we evaluate if the answers are correct?”.
By introducing RAG, we enforce the LLM to always answer solely based on the introduced context. The LLM will act as the reasoning engine, while the additional information added through RAG will act as the single source of truth for the generated answer. By doing so, we can quickly evaluate if the LLM’s answer is based on the external data or not.
Any LLM is trained or fine-tuned on a subset of the total world knowledge dataset. This is due to three main issues:
- Private data: You cannot train your model on data you don’t own or have the right to use.
- New data: New data is generated every second. Thus, you would have to constantly train your LLM to keep up.
- Costs: Training or fine-tuning an LLM is an extremely costly operation. Hence, it is not feasible to do it on an hourly or daily basis.
RAG solves these issues, as you no longer have to constantly fine-tune your LLM on new data (or even private data). Directly injecting the necessary data to respond to user questions into the prompts that are fed to the LLM is enough to generate correct and valuable answers.
To conclude, RAG is key for a robust and flexible generative AI system.
How a RAG system works?
let’s consider an example of how a RAG system works. For simplicity, let’s assume that the external memory is a database of documents, such as a company’s memos, contracts, and meeting notes. A document can be 10 tokens or 1 million tokens. Naively retrieving whole documents can cause your context to be arbitrarily long. To avoid this, you can split each document into more manageable chunks. Chunking strategies will be discussed later in this chapter. For now, let’s assume that all documents have been split into workable chunks. For each query, our goal is to retrieve the data chunks most relevant to this query. Minor post-processing is often needed to join the retrieved data chunks with the user prompt to generate the final prompt. This final prompt is then fed into the generative model.
References
Referenced in the eBook AI Engineering by author Chip Huyen and LLM Engineer's Handbook by authors Paul Iusztin, Maxime Labonne