Chroma: The Open-Source AI Application Database
To Nha Notes | April 28, 2025, 10:35 a.m.
Chroma is an open-source AI-native database built for modern AI applications. It combines vector search, embeddings management, document storage, full-text search, metadata filtering, and multi-modal retrieval — all in one unified platform. Designed with "batteries included," Chroma makes retrieval simple, reliable, and efficient.
Whether you are building LLM applications, RAG systems, or AI-driven products, Chroma empowers you to store, search, and retrieve not just text, but also images and other data types. Its deep support for metadata filtering and multi-modal embeddings means you can build sophisticated AI apps faster without piecing together multiple tools.
Key Features:
-
Embeddings Storage and Management: Store and manage high-dimensional vectors for fast AI retrieval tasks.
-
Vector Search: Ultra-fast nearest neighbor search across embeddings.
-
Document Storage: Easily save, query, and manage document collections.
-
Full-Text Search: Combine traditional keyword search with vector search for more flexible querying.
-
Metadata Filtering: Query documents or embeddings based on structured metadata alongside vector similarity.
-
Multi-Modal Retrieval: Retrieve images and other modalities, not just text.
Deployment Options:
-
Self-Hosted: Fully open-source under the Apache 2.0 license.
-
Chroma Cloud (coming soon): A fully managed, serverless, distributed cloud offering currently in private preview.
Chroma is simple to get started with for both Python and JavaScript developers, and it's actively building a vibrant open-source community around it.
Why Chroma?
-
Purpose-built for AI and LLM applications
-
Open-source flexibility
-
Batteries-included design (no need for stitching multiple services)
-
Growing cloud offering with serverless architecture
-
Active community and open contribution model
For developers building AI-native apps that need fast, accurate, and scalable data retrieval, Chroma is becoming the go-to choice.
There are other options such as Weaviate, Faiss, Milvus, or Pinecone. The first three are open source solutions, like Chroma, while Pinecone is a proprietary solution.
Main features of vector databases
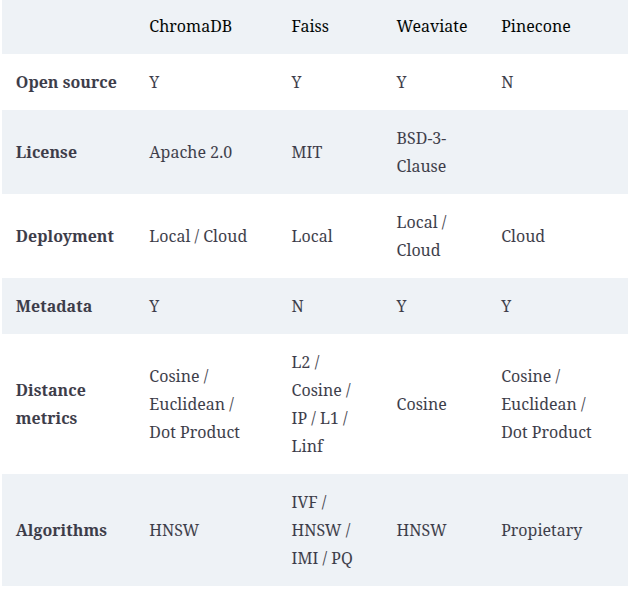
As you can see, the differences aren’t very significant. It’s true that all of them support different metrics to measure the distance between embeddings, but all of them support Cosine distance. Something similar happens with the sorting algorithms used; all of them, except Pinecone, which has its own, support HNSW.
The truth is that I’ve gotten used to using ChromaDB and Faiss. I use Faiss when I don’t intend to store the data on disk, just keeping it in memory, while ChromaDB is the one I use almost always, unless I’m in a project where they are using another one, or with a company that has a license or support with one of the manufacturers.
References
-
Pere Martra, Large Language Models Projects: Apply and Implement Strategies for Large Language Models